对于移动应用的保护,或者说“加固”,之前一篇文章开了个头,今天拿来大神小伙伴(网名 tick,tock)之前写的干货来和大家分享一下。
一、ARM 时代
在 Microsoft-Intel 统治的时代,Native 程序几乎都是 x86 架构的,经过多年的逆向与反逆向技术对抗,代码保护技术已经基本成熟,从最开始的压缩壳一直发展到虚拟机壳,实现了从文件级的整体保护到函数级的代码控制流保护。
但近年来,随着智能手机、IoT 设备的普及(是的,我们手里的手机,不管是 Android 还是 iPhone,基本上都是 ARM 的),移动应用兴起,基于 ARM 的 IoT 智能设备大量进入生产和生活,“加密-破解”的主战场也开始向 ARM 方向转移,开始从简单的“保护”向更高的安全强度发展。
由于安卓系统的开放性,代码安全问题表现最突出,近来市场上也出现了一些 所谓的“SO加固” 产品,其技术原理类似于 PC 端最早的“压缩壳”(需要补课的同学可以看上面那篇文章),就是将 SO 文件中的代码段压缩或加密,在入口函数中解密再执行。这种保护方式可以防止直接用反编译工具打开反编译,从静态看表面上是有效果的,但在运行过程可以直接被 dump 出来再反编译。后来还出现了“自定义 Linker”等方式的保护方式,这样可以隐藏一些文件格式信息,但依然解决不了 dump 后函数被反编译的问题。
由于文件级的整体保护方式无法应对更高等级的安全问题,开始出现了一些基于 LLVM 的代码混淆方式,多数此类产品基于开源的 OLLVM(由瑞士西北应用科技大学安全实验室在2010年发起的一个项目)改造,此后基于 LLVM 的代码保护技术成为了函数级保护的主流技术。
那为什么现有的 ARM 指令保护技术没有采用像 PC 端那样直接对指令进行保护,而是借助于 LLVM 框架来实现,这种保护方式是否更有优势呢?我们对这两种技术分别介绍一下。
二、基于 LLVM 的保护技术
技术原理
LLVM 广义上看是一个编译器框架,包含了从编译器前端(Clang)、中间语言(IR)、编译器后端、链接器整个链条,基于 LLVM 的代码保护技术主要通过向 LLVM 框架中添加混淆流程(Pass),对编译的中间语言 IR 进行混淆,最后通过 LLVM 编译器后端生成具体的平台相关指令,再链接成相应的可执行程序,大致流程如下图:
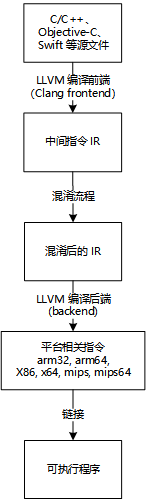
简而言之,就是在对中间指令 IR 处理,实现了如控制流扁平化、切分基本块、指令替换、虚假控制流等代码混淆功能,不用关心后端的平台相关指令,都交由 LLVM 完成。这样做有一个好处就是不需要再关心后端机器码的生成,只要是 LLVM 支持的后端架构都是支持,但是“成也萧何,败也萧何”,前端也必须是 LLVM 支持的编程语言也可以。
安全性分析
一图胜千言,下面以使用 OLLVM 保护一个 rc4 算法为例看一下。
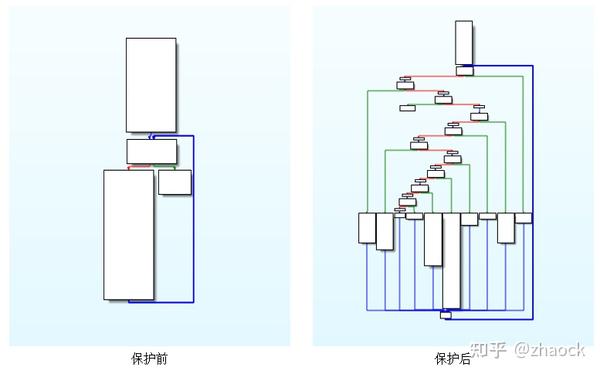
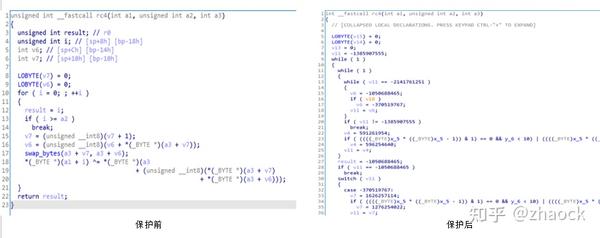
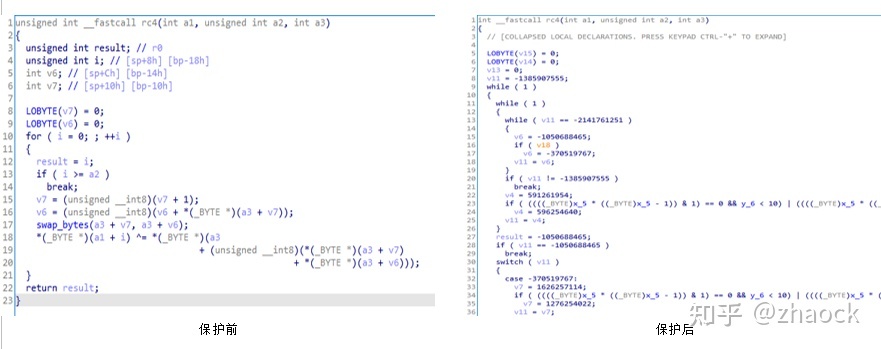
可以看出,被 OLLVM 保护后,代码逻辑确实变得更复杂难懂,的确起到了很好的防逆向分析作用,但仍然有以下不足:
- 依然可以被反编译
由于 OLLVM 是在编译过程中对 LLVM IR 进行了处理,IR 属于架构无关指令,在 LLVM 后端依然要生成平台相关的指令,所以最终只是变成了“更加复杂的 C/C++ 代码”而已。 - 边界清晰
经过“基本块”拆分,虽然函数中的逻辑块变得很分散,但它们依然排列在一起,函数有明确的起始和结尾。 - 函数间引用关系可见
混淆对象受限于 IR 指令,无法更精细地对 Native 指令进行操作,使得保护后的代码仍然可以被反编译工具用 “交叉引用” 搜索到,对函数间调用关系的保护效果差。
三、ARM-VM 保护技术
那么ARM 平台有没有和 X86 架构下想匹敌的保护呢,肯定是有的(不然也就不用写这篇文章了),ARM 架构也有虚拟机保护(ARM-VM)。
技术原理
ARM-VM 延续了 PC 端对 x86 指令的虚拟化保护思路,将其完整地适配到了 ARM 平台,该技术的实现完全独立,由单独的工具来实现,直接对编译生成的二进制文件进行保护。完整的技术实现,由解析,配置,编译(混淆、虚拟化),链接等几个步骤完成:


ARM-VM 技术位于上图的“编译”过程,通过将 ARM 指令翻译成自定义的虚拟机指令,并将虚拟机解释器和虚拟指令以指令块和数据块的方式插入“块表”中,最终链接成新的可执行程序,如下图所示:
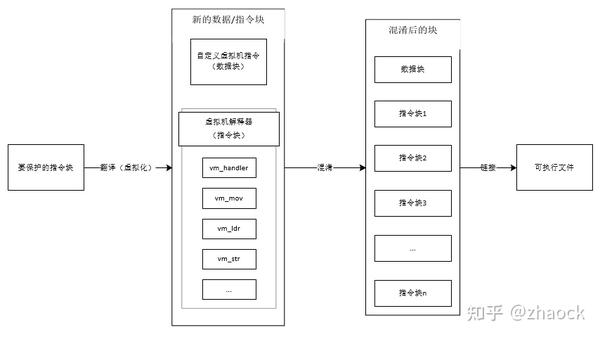
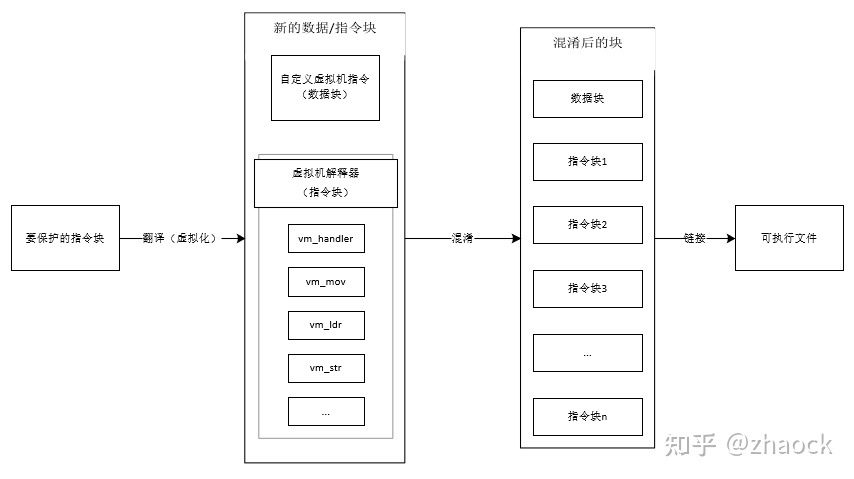
安全性分析
仍然是保护 rc4 算法 ,经过 IDA Pro 分析后,控制流和反编译效果如下:

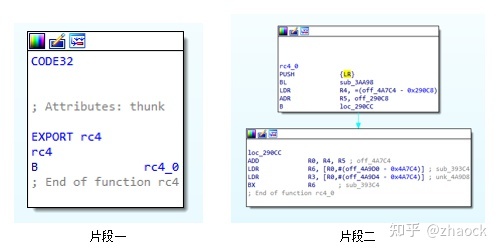
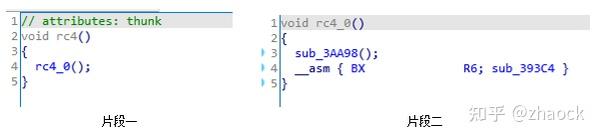
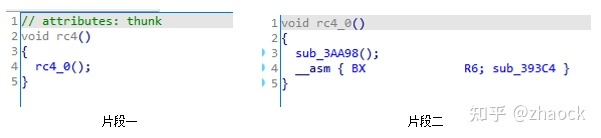
由于指令切片,间接跳转等原因,IDA Pro 只绘制出了“片段一”的控制流程图,再跟踪到跳转后的 rc4_0,继续查看控制流程图“片段二”,仍然不完整。
IDA 也无法反编译出真正的逻辑,通过反汇编分析,可以大致看到虚拟机的入口和自定义指令,但如果要分析具体的逻辑,需要分析每一条自定义的虚拟机指令,复杂度极高,可以往下体会一下:
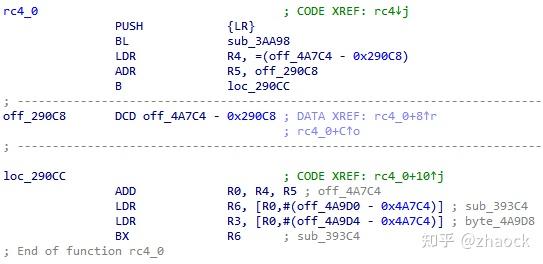
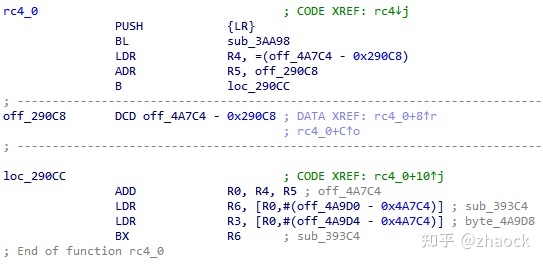
可以看出,ARM-VM 技术由于直接对 ARM 指令进行保护,具有以下特点:
- 无法被反编译
通过指令切片,间接跳转等处理,生成的指令块无法被 IDA 分析,只能查看汇编指令。 - 无函数边界
通过链接器乱序再重定位,生成的指令块在可执行文件中的位置是随机的,函数保护后变成了无数个随机位置的指令碎片,无法知道函数的边界。 - 更精细的保护粒度
直接对 ARM 指令保护,可以更精细的控制指令和寄存器,灵活性高,能够达到更高的安全性上限。 - 适应性高
直接处理 ARM 指令,不受限于开发语言和语法标准,几乎可以保护任何编译为 ARM 架构的程序,如 golang 等。
四、总结
技术最终要体现在产品上,基于 LLVM 的保护技术,产品一般以编译器的形式提供(不要觉得一提“编译器”就高级,那是巨人的肩膀),而采用 ARM-VM 技术的产品则以保护工具(也就是通常所谓的“壳”)的形式提供,下面对两种产品进行一下简单对比。
从适应性上说,各有优劣势,基于 ARM-VM 的程序保护只与 CPU 架构和二进制文件格式有关,对前端的语言没有要求,但是对于每一种CPU架构都要进行处理,所以对于一些相对不那么主流的架构就可能不支持(如MIPS);而基于 LLVM 的保护工具更好相反,只能支持 LLVM 前端支持的语言,但是因为 LLVM 的后端支持特别丰富,所以这方面不是问题。
重点看一下保护效果的对比:
| 基于 ARM-VM 的程序保护 | 基于 LLVM 的代码保护 | |
|---|---|---|
| 反编译效果 | 无法被反编译 | 可以被反编译 |
| 函数体边界 | 函数体保护后通过指令切片技术分布在二进制中的随机位置,无法直接确定边界 | 由编译器生成,函数边界清晰,函数间调用关系清晰可见 |
| 保护粒度 | 以汇编指令为粒度,保护针对每个指令,保护的灵活度和自由度高 | 以LLVM 中间语言 IR 为粒度,LLVM 后端会生成相应的汇编指令,灵活度差 |
可见在安全性方面 ARM-VM 具有压倒式的优势。
写在最后:在可用性需求满足的的情况下,总是应该优先选择使用 ARM-VM 技术保护应用,但是因为要处理 CPU 指令和不同系统的可执行文件格式,这种东西特别偏底层,现在大家都不太愿意沉下心搞底层了,对一个公司来说也可能出力不讨好,而 OLLVM 是一个相对“偷懒”的方案,这就是为什么现在 ARM-VM 产品少,而基于 OLLVM 的产品特别多的原因。
